
软件介绍
爬山虎采集器是一款简单易用、功能强大的网页采集软件,它能够采集互联网上的大部分网站数据,包括网页表格数据、文档、图片及其他各种形式文件,并自动批量下载到本地电脑。同时该软件还可以将采集的数据导出为各种格式文件、数据库、网站API接口,可以定时运行,自动发布,增量更新采集,完全实现自动化运行,无需要人工干涉,极大提高人们从互联网上获取数据的效率。如果您需要对某个指定网页数据进行采集,不妨来下载爬山虎采集器试试!
通过可视化界面、鼠标点击即可采集数据、向导模式、用户无需任何技术基础,输入网址,一键提取数据。
2、独创高速内核
内置一套高速浏览器内核,加上HTTP引擎、JSON引擎模式,实现快速采集数据。
3、定时运行
可以按照每分钟、每天、每周、以及CRON表达式。指定了计划任务,任务就可以实现自动采集、自动发布,无需人工操作。
4、智能识别
通过智能算法,自动识别分页,自动识别列表,一键采集数据。
5、支持文件下载
可以支持图片、视频、文档等各种文件下载,支持自定义保存路径、文件名。
6、多种数据导出
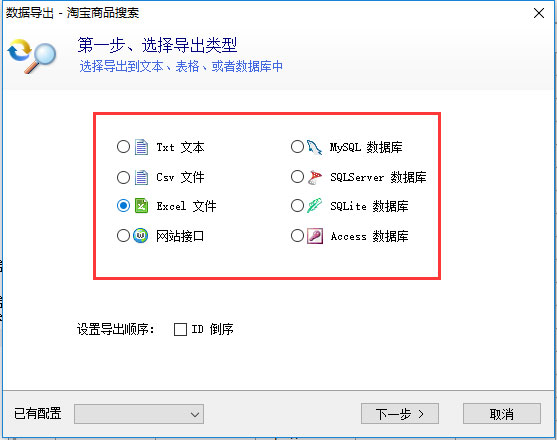
支持多格式数据导出,包括TXT、CSV、Excel、ACCESS、MySQL、SQLServer、SQLite及发布到网站接口(Api)。
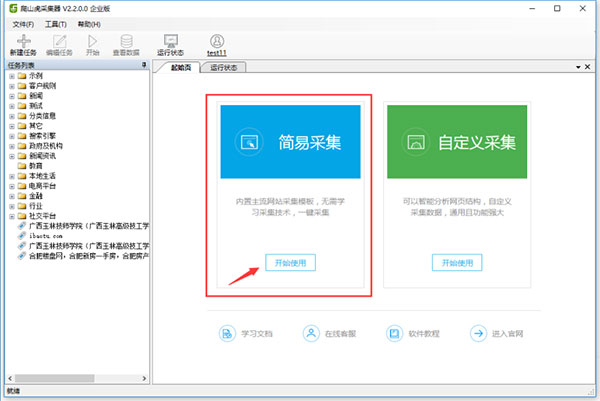
第一步:打开客户端,选择简易模式
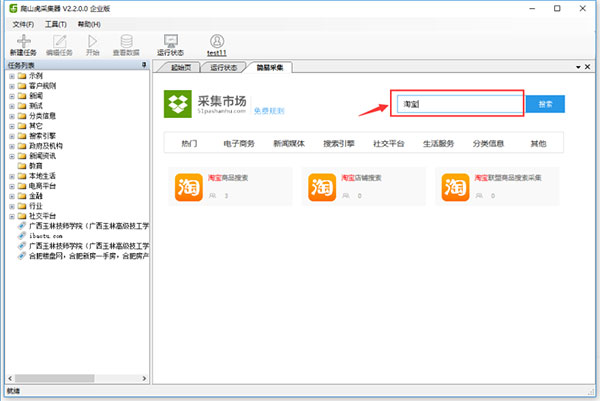
选择相应的采集模板

也可以根据入关键词搜索,筛选对应的模板分类
第二步:预览模板的采集字段和示例数据
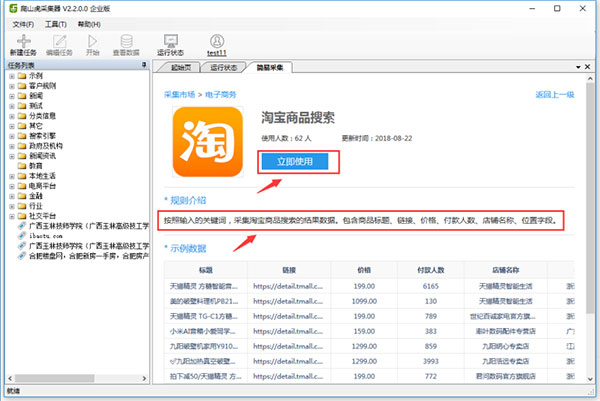
根据提示,输入对应的参数(此模板是输入需要采集的关键词)
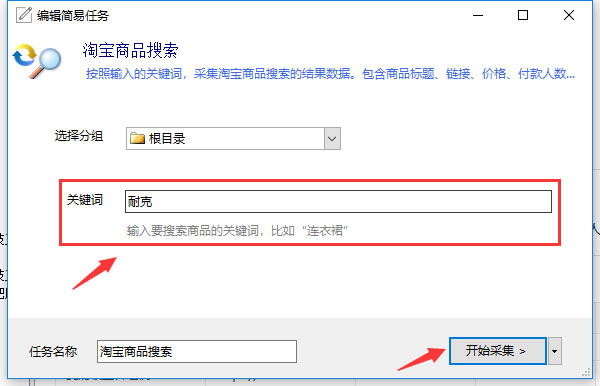
第三步:运行并下载
开始即可查看加载的进程
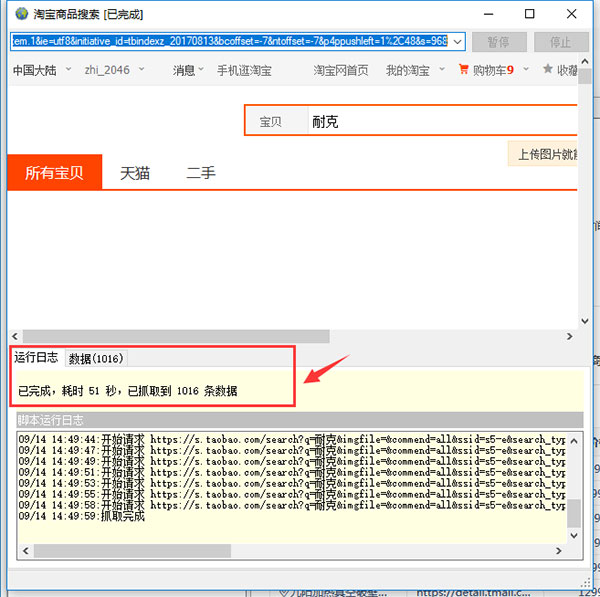
任务列表中:选中任务/点击查看
选择合适的保存格式
二、如何使用高级过滤,筛选关键词采集数据
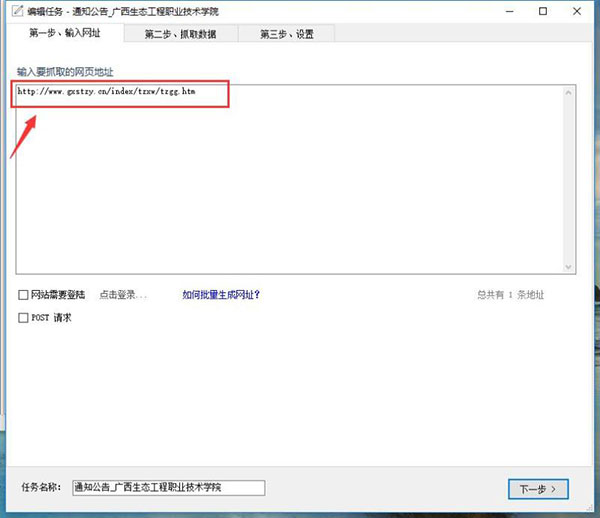
第一步:新建任务,进入主页,选择“新建任务”输入需要采集的网址。
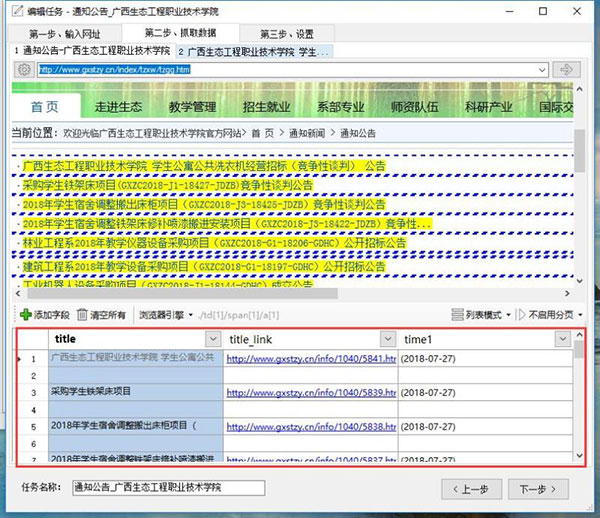
第二步:抓取数据
采集器自动识别列表数据 自动识别分页(需要采集多页数据)
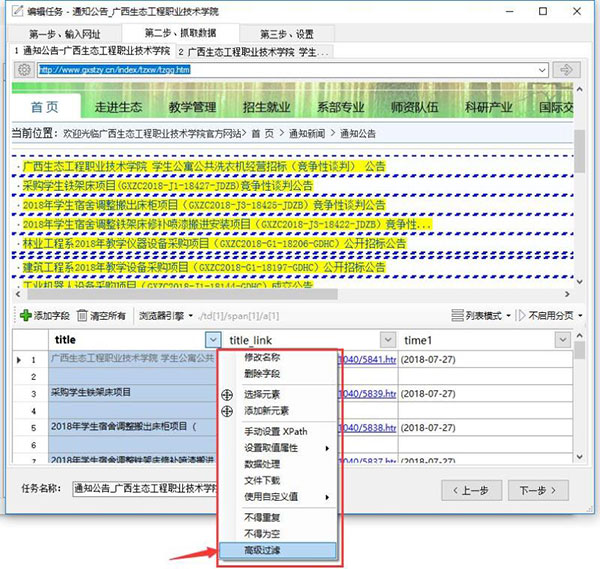
点击标题列/右键/高级过滤(可以根据需求自定义添加删除字段,修改名称等)
必须包含
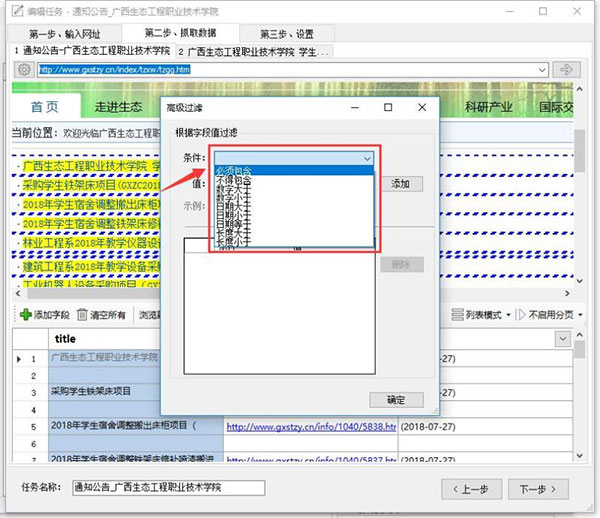
输入关键词:教学仪器设备,添加确定即可
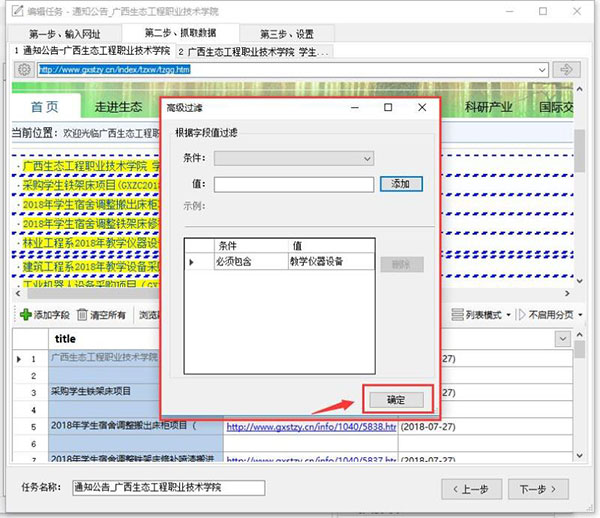
可以看到,不包含关键词的名称已删除,需要采集多页:自动识别分页
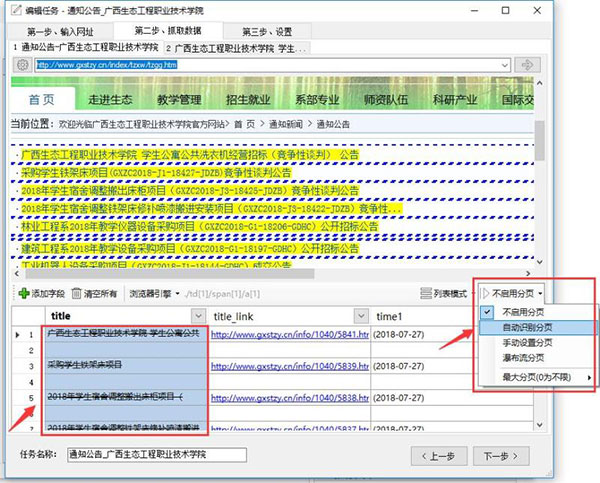
选中链接/深入此链接(需要采集关键词的内容页)
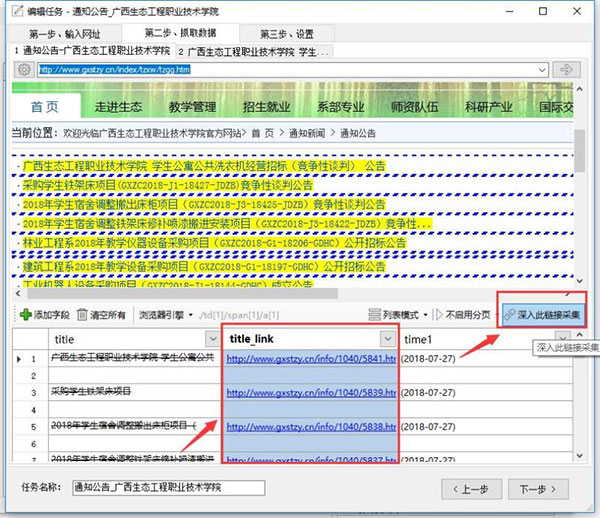
添加字段/点击选中全文

第三步:设置 根据需要,自定义设置,可以大大提高加载速度及工作效率。
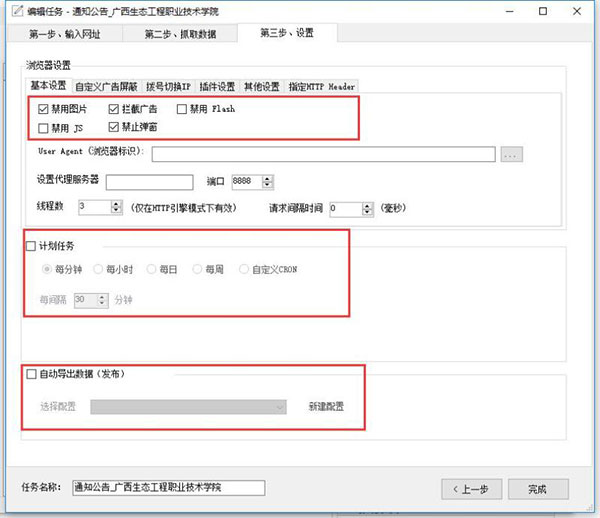
第四步:加载数据 任务列表中:选中任务/点击开使
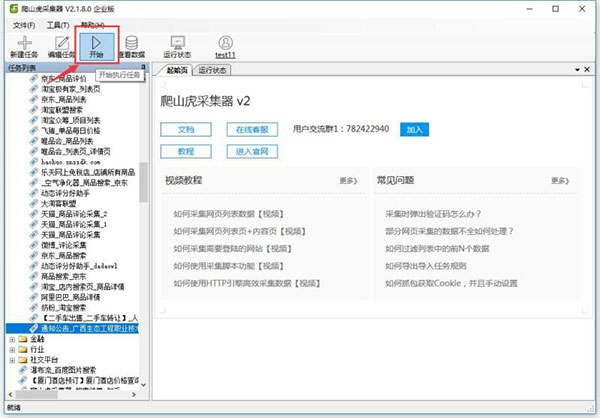
可以看到加载的进程 (点击数据也可以查看刚加载的数据)
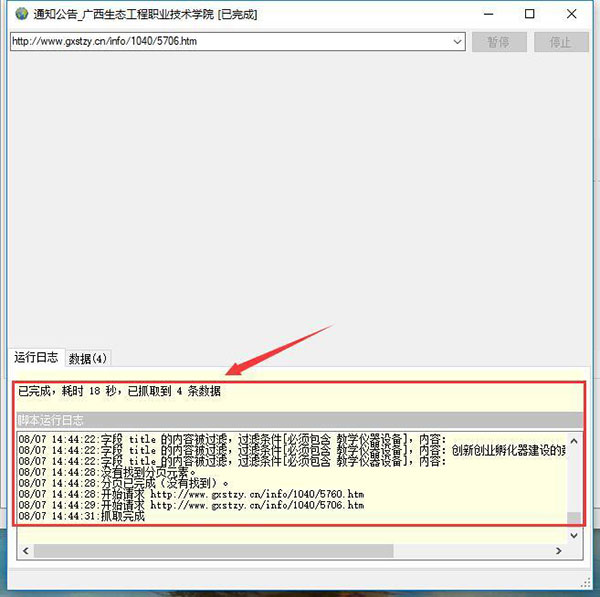
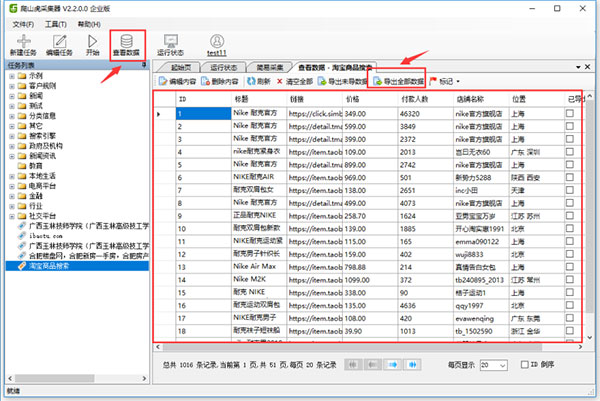
第五步:查看保存数据 任务列表中:选中任务/点击查看
可以预览刚加载的数据,并导出数据
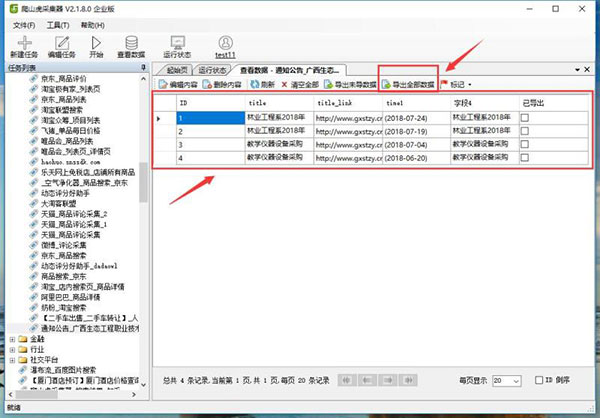
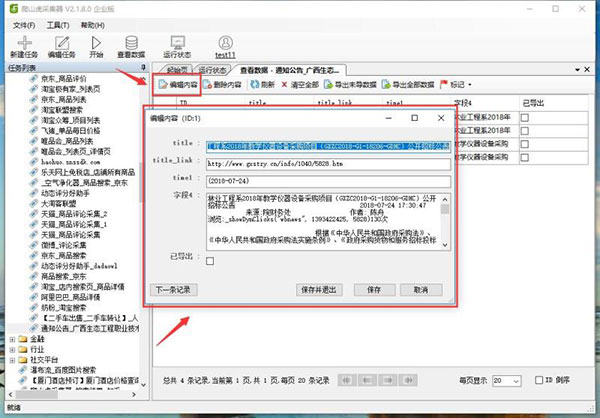
特殊情况 :编辑内容,可以预览全部数据(修改后统一下载 )
修复浏览器跨域问题
修复一个验证码问题

功能特色
1、向导模式通过可视化界面、鼠标点击即可采集数据、向导模式、用户无需任何技术基础,输入网址,一键提取数据。
2、独创高速内核
内置一套高速浏览器内核,加上HTTP引擎、JSON引擎模式,实现快速采集数据。
3、定时运行
可以按照每分钟、每天、每周、以及CRON表达式。指定了计划任务,任务就可以实现自动采集、自动发布,无需人工操作。
4、智能识别
通过智能算法,自动识别分页,自动识别列表,一键采集数据。
5、支持文件下载
可以支持图片、视频、文档等各种文件下载,支持自定义保存路径、文件名。
6、多种数据导出
支持多格式数据导出,包括TXT、CSV、Excel、ACCESS、MySQL、SQLServer、SQLite及发布到网站接口(Api)。
爬山虎采集器怎么用
一、如何使用【简易模式】采集数据第一步:打开客户端,选择简易模式

选择相应的采集模板

也可以根据入关键词搜索,筛选对应的模板分类

第二步:预览模板的采集字段和示例数据

根据提示,输入对应的参数(此模板是输入需要采集的关键词)

第三步:运行并下载
开始即可查看加载的进程

任务列表中:选中任务/点击查看

选择合适的保存格式

二、如何使用高级过滤,筛选关键词采集数据
第一步:新建任务,进入主页,选择“新建任务”输入需要采集的网址。

第二步:抓取数据
采集器自动识别列表数据 自动识别分页(需要采集多页数据)

点击标题列/右键/高级过滤(可以根据需求自定义添加删除字段,修改名称等)

必须包含

输入关键词:教学仪器设备,添加确定即可

可以看到,不包含关键词的名称已删除,需要采集多页:自动识别分页

选中链接/深入此链接(需要采集关键词的内容页)

添加字段/点击选中全文

第三步:设置 根据需要,自定义设置,可以大大提高加载速度及工作效率。

第四步:加载数据 任务列表中:选中任务/点击开使

可以看到加载的进程 (点击数据也可以查看刚加载的数据)

第五步:查看保存数据 任务列表中:选中任务/点击查看

可以预览刚加载的数据,并导出数据

特殊情况 :编辑内容,可以预览全部数据(修改后统一下载 )

更新日志
v3.1.0.5版本修复浏览器跨域问题
修复一个验证码问题
用户评论
共0条评论
 赣公网安备36010602000086号,版权投诉请发邮件到website-sun@qq.com,我们会尽快处理
赣公网安备36010602000086号,版权投诉请发邮件到website-sun@qq.com,我们会尽快处理